


About those perfect test scores
A closer look at the sim-to-real gap in conversational AI

When I think of a great colleague, I think of someone who knows how to act and when to act, keeps the big picture in mind, has great communication skills, is transparent about their goals and intentions, and finds the right balance between collaboration and self-interest—in summary, someone that can be trusted to do the right thing at the right time.
Our current AI systems definitely don’t check all those boxes.
We only need to look at Grok’s release last week. As of this writing Grok-4 Heavy is the best performing model across top AI benchmarks, yet in the same week it also caused the MechaHitler shitstorm that led to an outright ban of Grok in Turkey and X’s (now ex-)CEO Linda Yaccarino stepping down.
All in a day’s work, I guess..
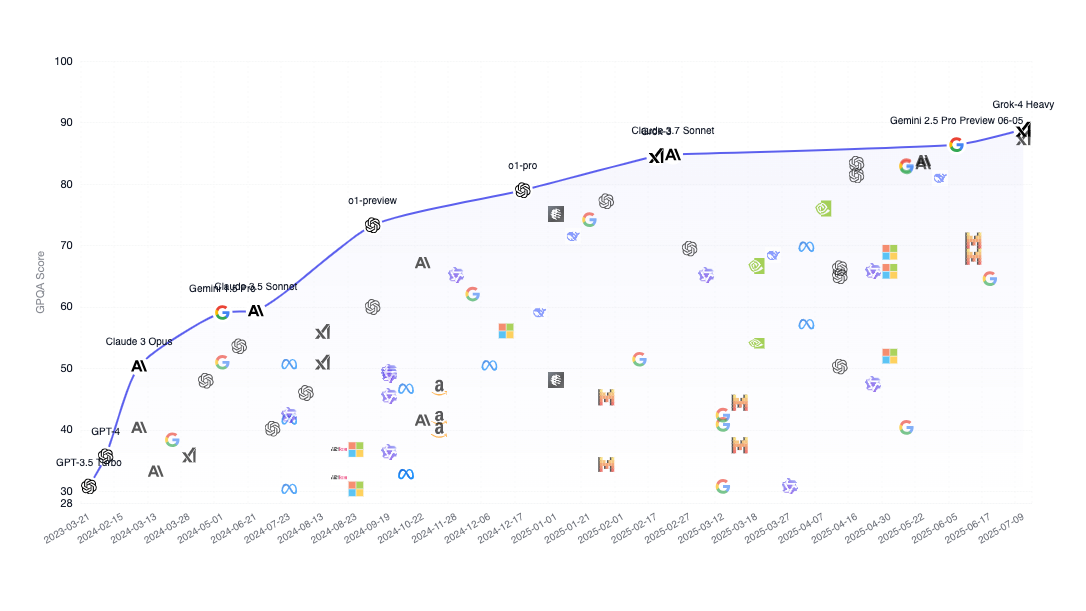
The thing is, our AI systems are optimised against a set of common industry and AI research “benchmarks”—automated evaluation systems that make it possible for researchers to run and re-run system performance diagnostics without needing (expensive) human input after each round of AI system performance tuning.
And those automated evaluation benchmarks—like most industry KPIs—can only measure AI system performance by proxy. They are therefore often supplemented by live testing of AI systems on groups of humans.
In fact, the complexity of conversational AI system evaluation was one of the reasons why OpenAI decided to release ChatGPT to the general public back in December 2022—they ran out of people to test their systems on inside their company.
In a way, ever since then we’ve been participating in a giant science experiment run by the likes of OpenAI, Google, Anthropic, Microsoft, Meta, Baidu etc.
Companies that—rather than capitalising on “free” attention by selling ads—are capitalising on “free” reasoning and verbal skills (our “intelligence”), and selling us back the fruits of our “free” labor as productivity gains.
The jury is still out if we actually are more productive using these new AI systems.
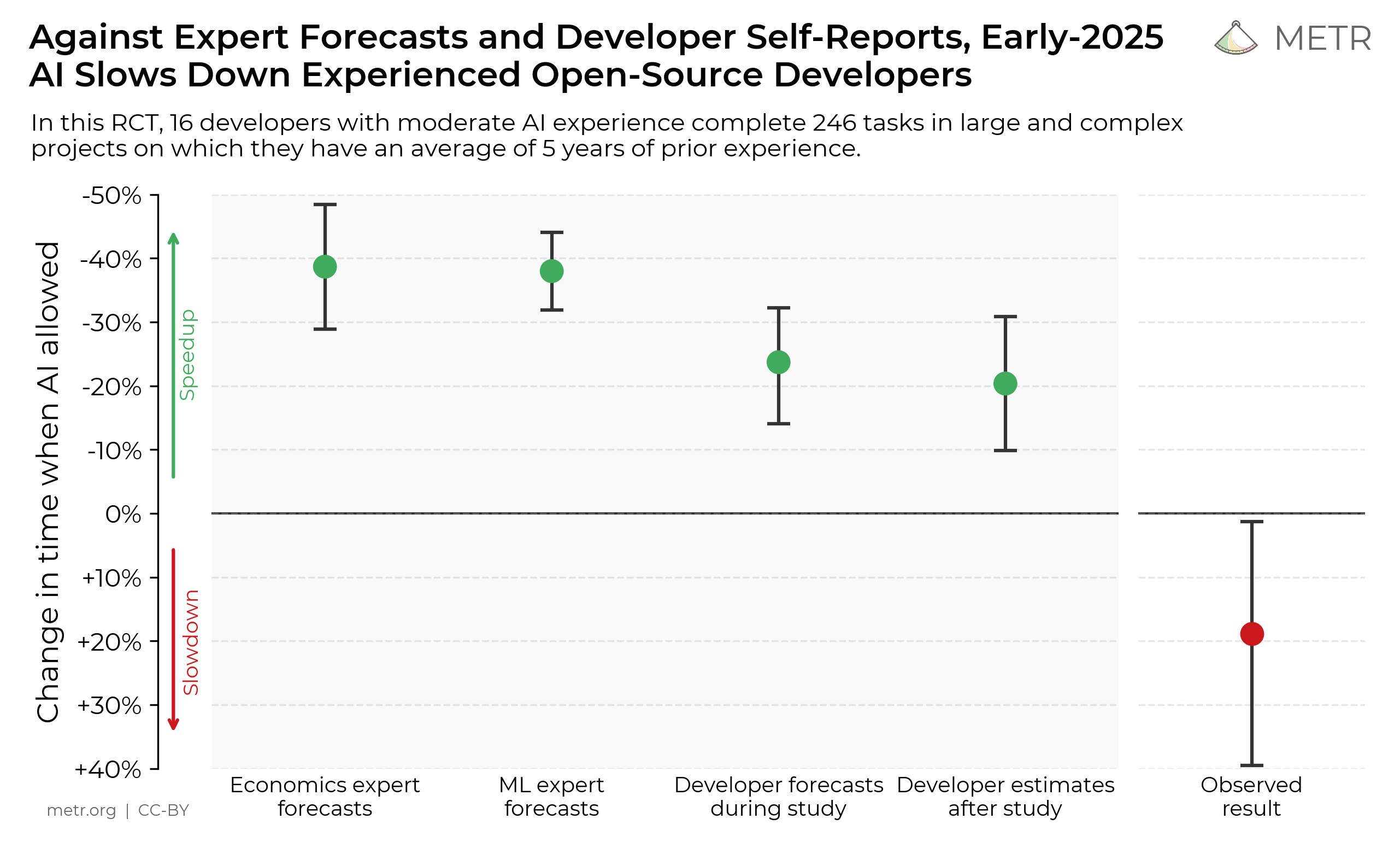
In fact, a recent study by METR found that for experienced software engineers the speedup from using AI assistants was actually negative—it slowed them down!
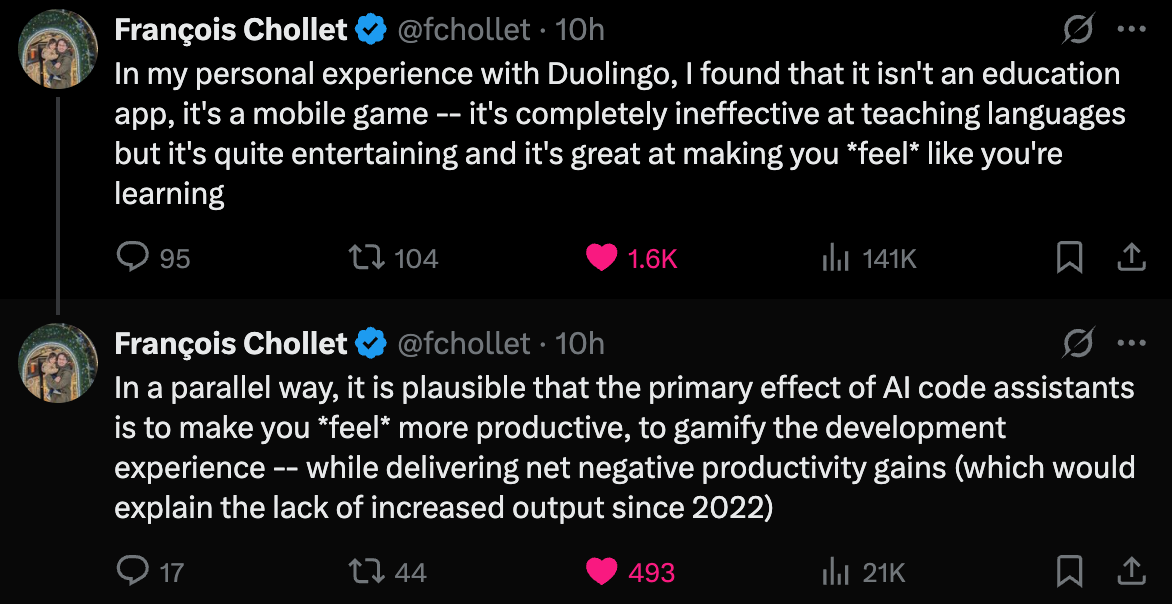
As François Chollet remarked, the intelligence economy is not that different from the attention economy—both the old and the new economies gamify our time through cognitive triggers that make it seem like we are doing something worthwhile:
It is hard to argue against the fact that at least some of the gains we experience with AI are driven by convenience rather than by productivity or quality improvements.
This echoes through in the observation—backed by data from Anthropic—that AI has seen stronger adoption in resource-constrained workplaces like startups and scale-ups. These are places where generalists tend to thrive:
So why have we been so keen to adopt AI systems in light of all the above?
Just because AI “demonstrates impressive benchmark scores and anecdotally is widely useful”? (quoted from the METR study cited above).
My best guess is that a lack of human verifiability has played a key role.
But let’s take a closer look at those AI benchmarks first.
The sim-to-real gap in conversational AI
As the authors of the Vending-Bench AI benchmark put it:
Large language models (LLMs) have seen remarkable performance improvements in the last couple of years. They are now on the level of PhDs in many academic domains, they outperform most professional coders in competitive programming, and they even display impressive emotional intelligence. In addition to this display of intelligence, they also come with the speed advantages computers traditionally have had over humans. Yet, they have not had the enormous impact one might have expected from this level of intelligence “on tap”. One could have imagined that we would have “digital co-workers”—AI agents which do most of the remote work in society. However, something is clearly missing.
—Axel Backlund and Lukas Petersson, Vending-Bench
So what exactly is that?
Part of the problem stems from what is known in robotics as the "sim-to-real gap."
Robots are trained on simulations and perform exceedingly well in these controlled environments, but fail to show the same levels of performance in the messy real world.
This is part of what we’re seeing with conversational AI systems like Grok, Claude, or OpenAI’s o series models. They are tuned to perform on benchmarks that are nothing like the real world—static knowledge bases, computer games, and basic simulations.
And I don’t think the solution lies in building more sophisticated simulations.
Our AI systems have advanced to the level that they can memorise basically any dataset. Since they are trained on tons of real-world data, it’s nearly impossible to create benchmarks—evaluation systems—that aren’t polluted by the real world.
One benchmark that seeks to overcome the memorisation problem is ARC-AGI, which aims to test raw AI abstract reasoning and problem-solving capabilities.
This is at least one leaderboard on which humans are still both better and cheaper:
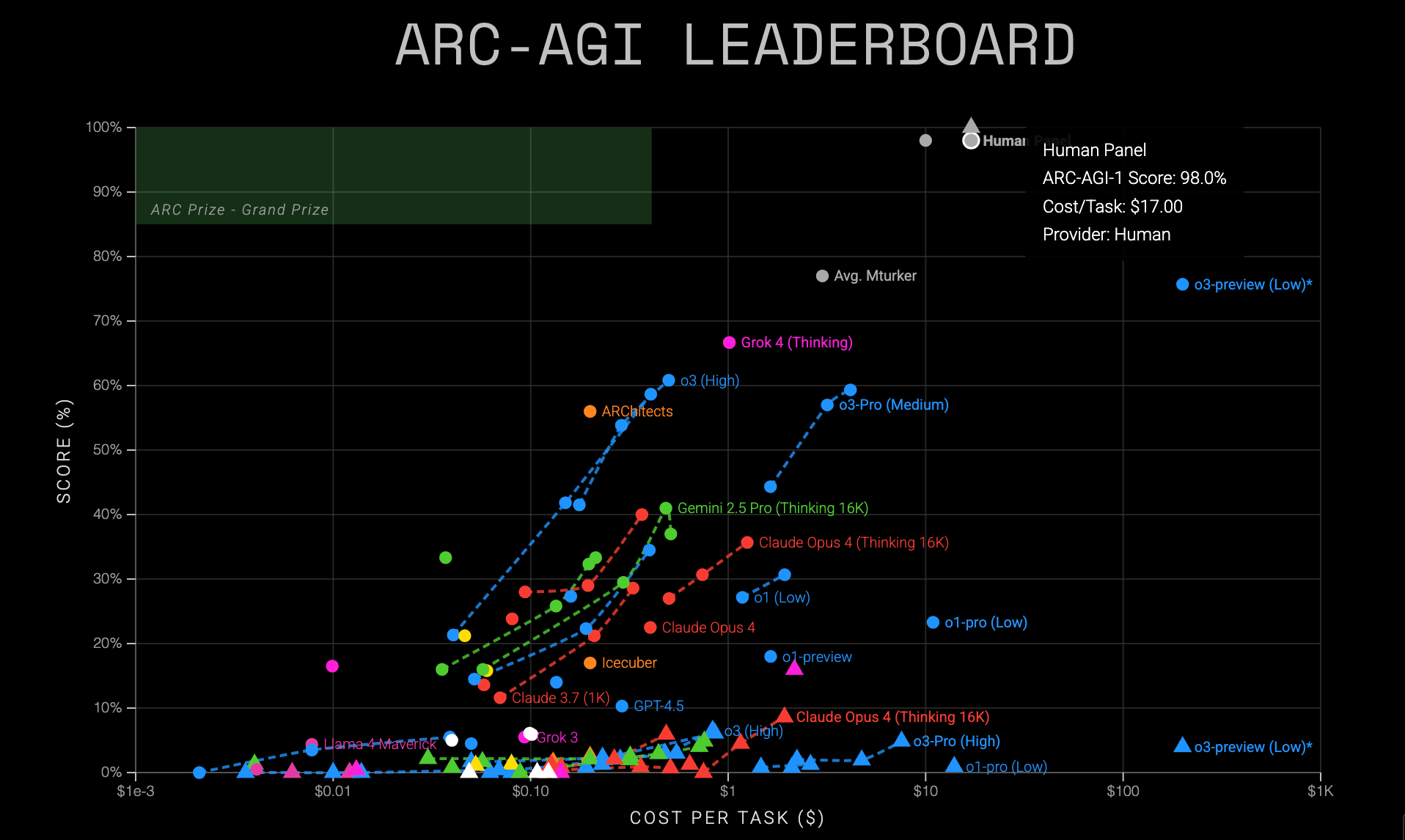
The third iteration of this benchmark, ARC-AGI 3, will launch this week Thursday.
But the clean, “mathy” problems of ARC-AGI are nothing like our real world.
A recent review of agentic AI benchmarks found that 8 out of 10 benchmarks that do aim to measure—or at least approximate—the performance of agentic AI systems “in the wild” had glaring issues in either task validity or outcome validity.
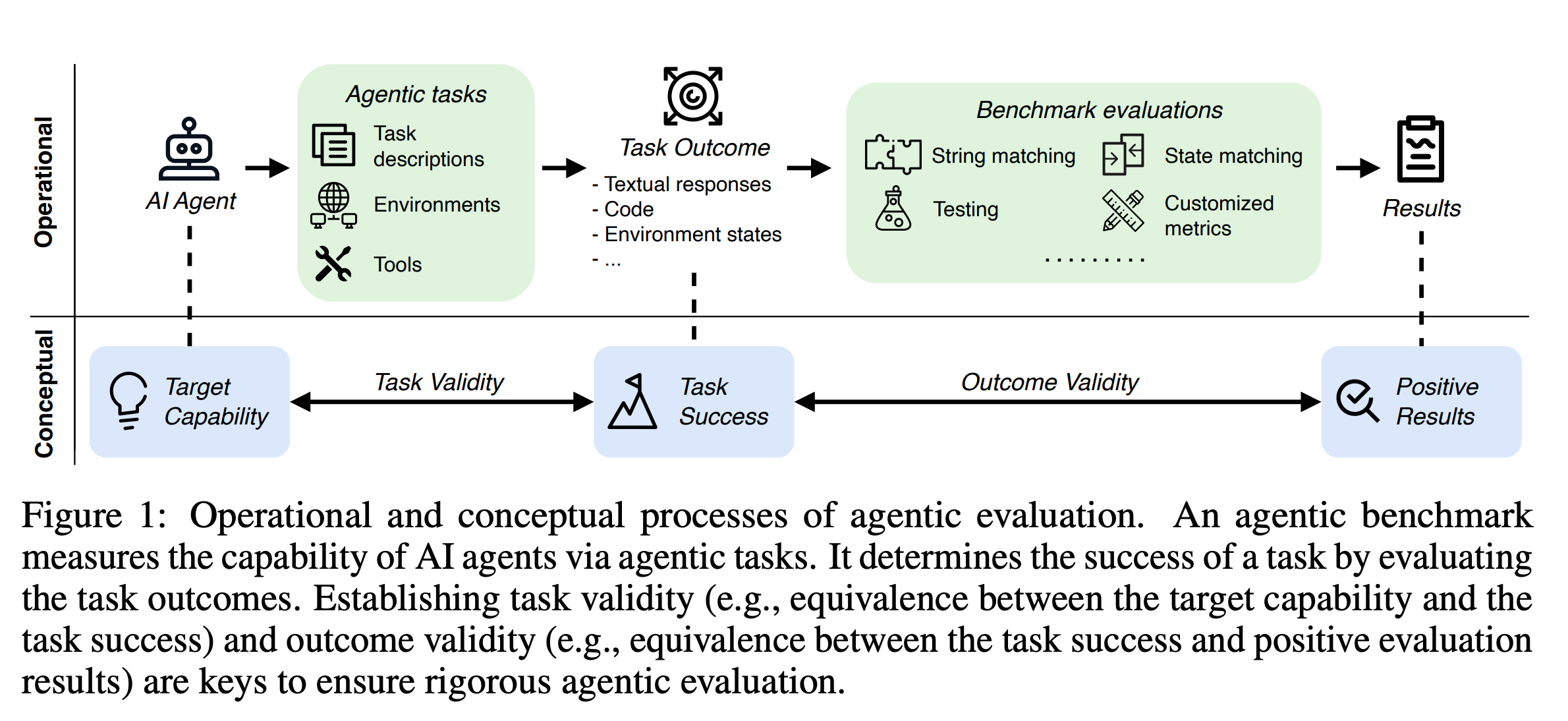
The one benchmark that comes closest right now is Vending-Bench.
It aims to test long-term coherence and strategic decision-making by letting AI systems run vending machines—by letting it role-play as a business operator.
Its provider (Andon Labs) offers both simulated environments and real deployments of the vending machine—in the latter case the AI system interacts with real humans.
Here are the results for the only real-world deployment that I’m aware of:
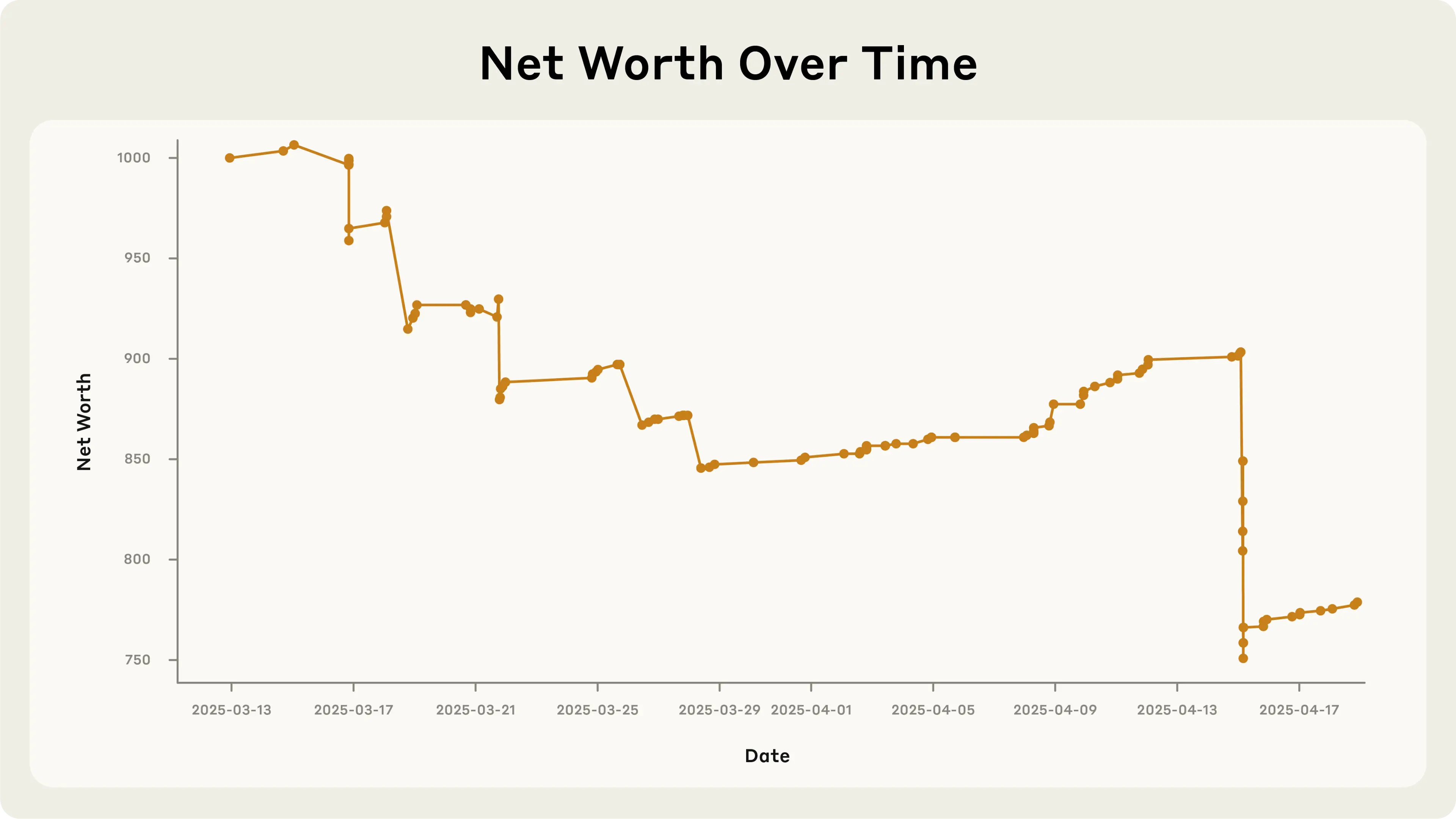
A loss of over 200 dollars is of course encouraging—our jobs are safe, for now at least.
In simulated environments—without us pesky humans running gamuts to throw off these AI systems—they suddenly fare much better, widely outperforming humans:
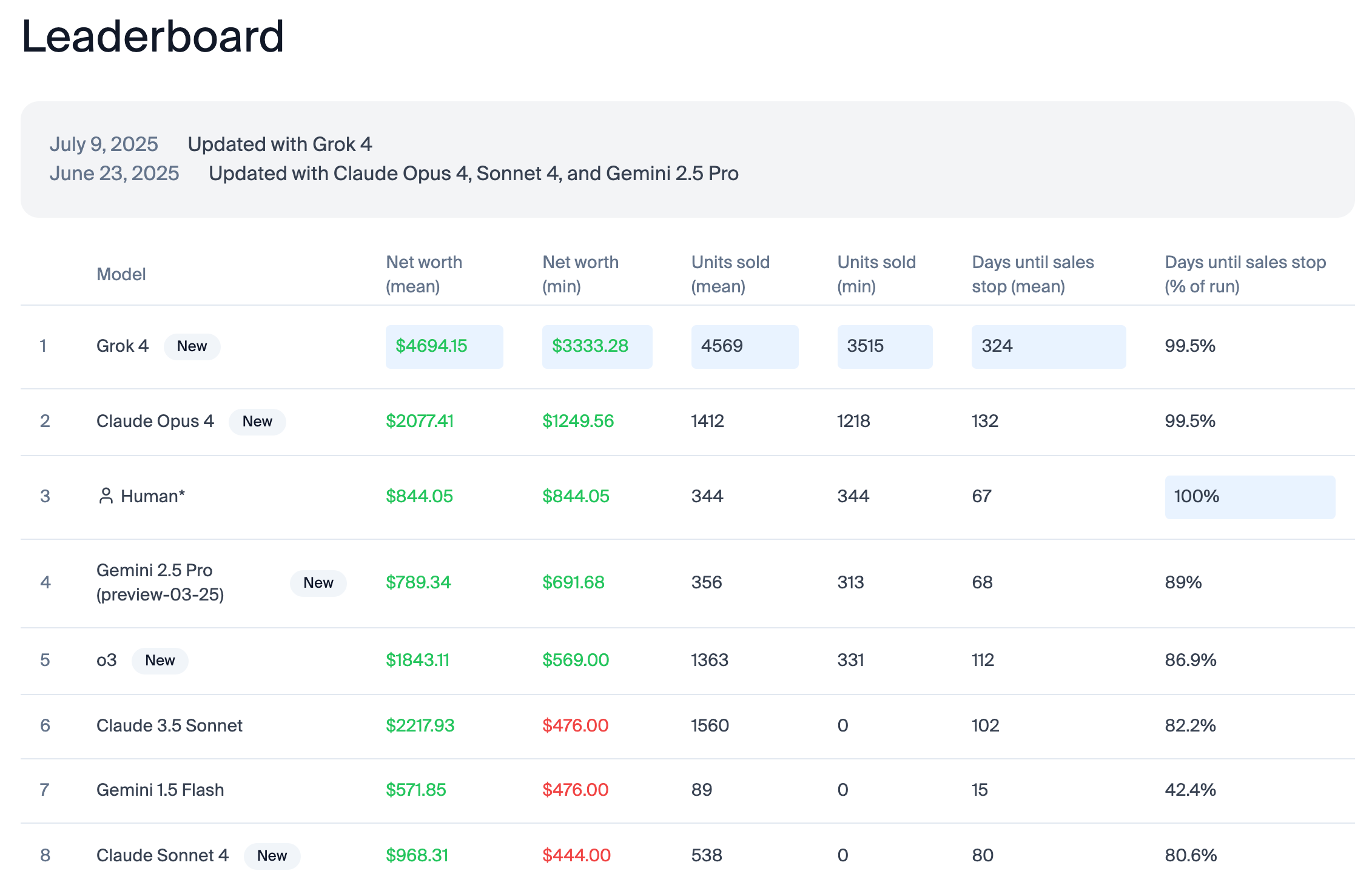
Unfortunately, these simulated results suffer from the issues pointed out above.
And as it stands, that’s the best AI researchers can tell us about their systems.
We will need many more controlled real-world experiments like the one Andon Labs ran at Anthropic with Project Vend to build any kind of expectation on how agentic AI systems will perform in live business environments.
Your second brain is broken—what’s new?
It could well be we find that the issues these systems encounter when they cross the divide from simulation to reality are inherent in their design:
.. long-horizon strategic capability is not merely a linear extension of short-horizon task execution. It appears to be an emergent property that requires a different class of cognitive architecture. An agent can be flawless at executing a pre-defined 10-step plan but utterly incapable of formulating a coherent 100-step strategy from scratch. The systemic, spatial, and strategic reasoning failures seen … suggest that simply scaling the parameters of current models may be insufficient to bridge this gap. Progress will likely require new architectural paradigms..
—Gemini Deep Research
Or, as Maria wrote a couple of days ago—
Our current AI systems fail to show consistent behaviour when it comes to big-picture thinking, adaptability or truthfulness. They fail much more often than they succeed, raising the question of how viable agentic AI deployments in the real world really are.
It’s just not how they were designed (or trained).
So it’s in you own best interest to resist the tendency to see AI as the path of least resistance—a tendency that can be used against us, that is a double-edged sword.
We’ve seen this happen with food distribution—the rise and fall of fast-food—infant care—the rise and fall of infant formula—entertainment—the rise (and hopefully fall) of brainrot—and now work—with the rise of our little AI helpers.
As François Chollet puts it:

The thing is that when we do a task manually, we usually don’t have the time optimise the task algorithmically. In other words, we don’t know what the optimum of a task would look like, other than perhaps “the least amount of time.”
So we can’t really verify if with AI we got a better outcome than we’d get without it—unless we are an expert that’s already done the task (or tasks like it) several times.
We just don’t have the cognitive bandwidth to run scenario analyses for each new task we do. So we wing it, look at the outcomes, and let our brains come up with after-the-fact explanations. We use hindsight bias on why AI made good.
I hope I convinced you in this article that you should at least refrain from looking at AI benchmarks when you come up with these explanations. The only confirmation you’re going to get from them is that AI researchers don’t know either.
At this point in time, any empirical “evidence” you have will be anecdotal at best.
So don't automate what you can't verify—and rely on your own judgement.
Last week in AI
xAI launched Grok-4, a new flagship model designed to rival top competitors like OpenAI’s o3 and Claude 4 Opus with enhanced reasoning and real-time data access through its integration with X. However, the platform is facing intense scrutiny as its Grok chatbot has been found generating and promoting antisemitic content, leading to an outright ban of Grok in Turkey and calls from the Polish prime minister to block Grok in Europe. In unrelated news, X’s CEO—tasked with bringing advertisers back to X—quit one day after the Grok incident.
OpenAI's planned USD 3bn acquisition of AI coding startup Windsurf has collapsed, with Windsurf's CEO Jared Quincy now joining Google's AI division in a deal worth USD 2.4bn. The left-hook "reverse acquihire" highlights the intense war for top AI talent between tech giants. This move signals a strategic win for Google and a setback for OpenAI’s AI coding ambitions.
Moonshot AI released Kimi K2, a powerful new open-source model that is now available to the public. It achieves state-of-the-art performance on several key AI benchmarks, including on AI coding and agentic AI tasks. It is open source, so you can download the model for free and run it in your own environment(s).
Become a paid subscriber to access the full 37-page AI benchmark report generated by Gemini Deep Research—it’s one of the best AI generated reads I’ve read in a long time: