
How I Automated My Newsletter Research
And scan 100s of newsletters and transcripts every week

A collab with seven other creators I did recently made me realize I need to step up my game when it comes to tracking trends and gathering insights from online content.
I’ve been putting off building a newsletter scraping automation because I didn’t like the idea of AI systems reading AI newsletters to produce more AI newsletters.
Not exactly the type of circular economy I want to support.

The thing that finally convinced me was that—besides providing my readers with better insights in the “Last week in AI” section—such a setup would also allow me to identify trends and patterns for AI apps to build much faster.
The solution I ended up cobbling together yesterday consists of two parts:
Content capture and processing automations in Make.com
Interactive content analysis with Claude Code and Python
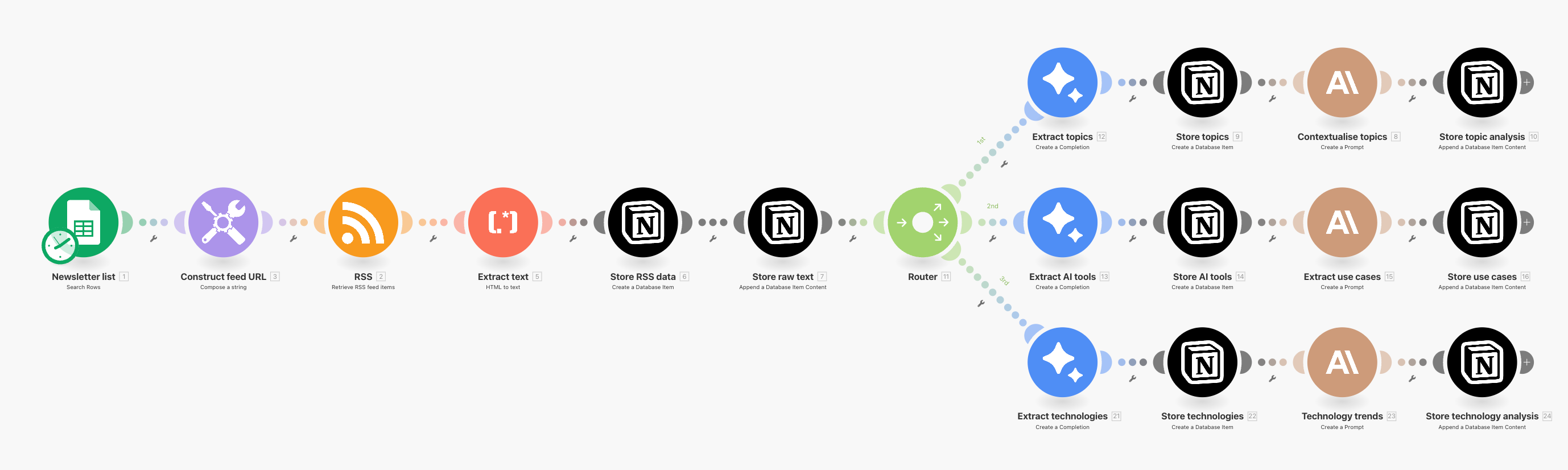
This is the Make.com scenario that downloads and processes Substack articles:
I’ve created a similar automation for capturing Youtube video transcripts via RSS:

Content capture via RSS
To track articles published by Substack newsletters I decided to hook into their RSS feeds—
from AI maker convinced me of the approach in this great write-up.RSS (Really Simple Syndication) is a standardized way to publish content feeds on the internet. It’s supported by both Substack publications and Youtube channels.
If you’re still at a loss, just add `/feed` to the URL of any Substack homepage in your browser to see what it looks like.
While a pretty common format, RSS isn’t always supported. For newsletters not on Substack I’ll still need to set up a dedicated inbox.
The newsletters in the "Newsletter list” Google sheet module of the Make.com scenario above are a mix of Substacks I already subscribed to and Substacks found through awesome Substack sleuthing by
(thank you Jurgen!).The RSS module is configured to filter RSS feeds on publication date:
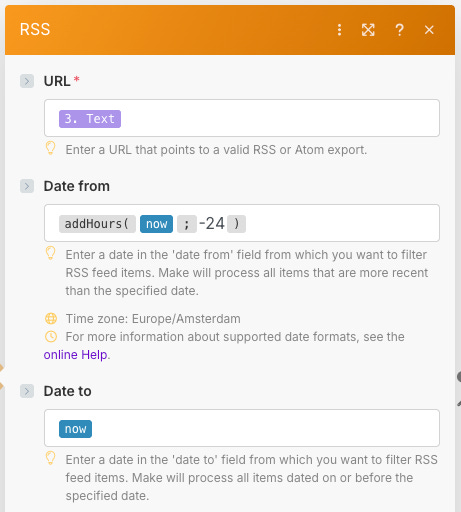
The Make.com scenario is triggered to run daily at 6 AM. This gives me a curated Substack feed available to scan and read in Notion every morning—analyzed and tagged for quick scanning, and with the full text available to read the article.
Make.com is a bit slow in terms of processing speed, but the main downside I ran into bulk processing articles (129 in seven days) was that I quickly hit the limit in number of operations in the Make.com free tier.
You can of course build everything locally in Python, but then you’d also need to build (or generate) monitoring and whatnot and arrange for hosting, so I opted to finally become a paid subscriber to Make.com after using it for free for a year. 🎻
I’m on the lightweight tier, which goes for around EUR 10/mo—worth it for me.
Extracting topics from newsletter articles
To extract topics from the articles I use two AI nodes in Make.com.

I) A Google Gemini Flash 2.5 chat completion
This is the systems prompt I use in the Extract topics node:
Your job provide topic intelligence for an AI and automation publication by identifying all the topics discussed in articles published by other publications in AI and technology.
Select the most prominent topics discussed in the publication, if any.
Example topics include:
Advertising, Agents, AI film making, AI safety, Automation, Business, AI coding, Economics, EU, Marketing, Psychology, Technology, VGM (video generating models).
You can expand the list if it doesn’t cover the key topics and themes discussed in the article, but make sure your topic name is max. 2 words long.
II) An Anthropic Claude 4.5 chat completion
For the Contextualise topics node, I wrote the following prompt:
You are working for an AI and automation publication called The Circuit, and your job is to provide content intelligence by identifying key discussion topics in articles published by other AI & technology publications. Only focus on long-term key trends, and extract max 3-4 topics per article.
This is the full text of the article:
…
Write a brief and concise one-paragraph summary for each of the identified key high-level themes and topics. The summary should be max three short sentences with the what, why, and how. Don’t focus on details and specifics, keep it general and high-level.
Only return the paragraphs of contextualised topics, one for each of the topics including context, opinions and predictions made by the author for that topic.
This will result in the following output for an article like the one by Wyndo:

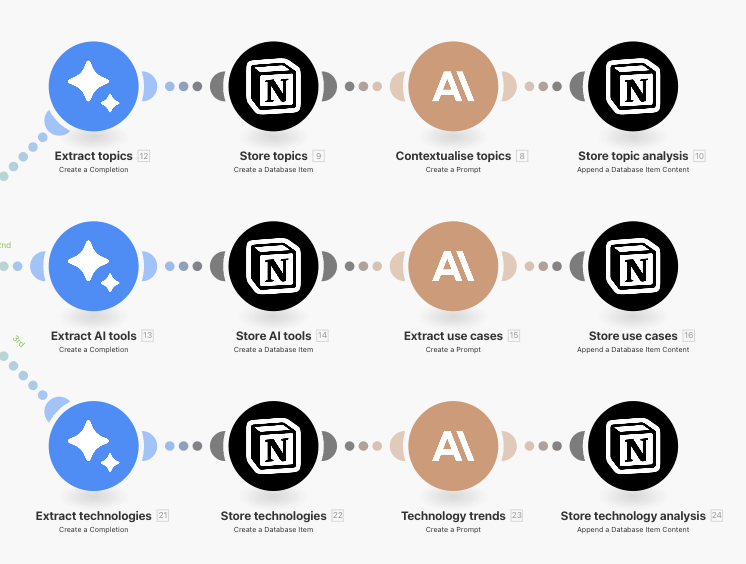
The AI models boil down each of the 100+ articles published last week to a set of topics, AI tools and technological breakthroughs that I can analyze using AI models, ML techniques—or just by reading the summaries myself.
The summaries are saved to dedicated Notion databases along with article metadata:

Similar branches in the scenario scan for AI tools mentioned and technological breakthroughs discussed in the articles so I can also track those over time.
If you’re interested in the full Make.com Substack RSS feed automation blueprint including all the prompts and node configurations, it is available to download for paid subscribers:
Interactive content analysis with Claude Code and Python
For the content analysis itself I figured I’d get to insights quicker if I ran some good ol’ fashioned topic analysis algorithms on the generated summaries.
I asked Claude Code to generate a small Python CLI (Command Line Interface) app that downloads the summaries from Notion and runs a simple UMAP topic analysis algorithm on the extracted topics, tools and technological breakthroughs.
For today’s newsletter, here’s one of the insights the Python app generated:

In my newsletter research workflow, I run this Python app as part of an 8-step process:
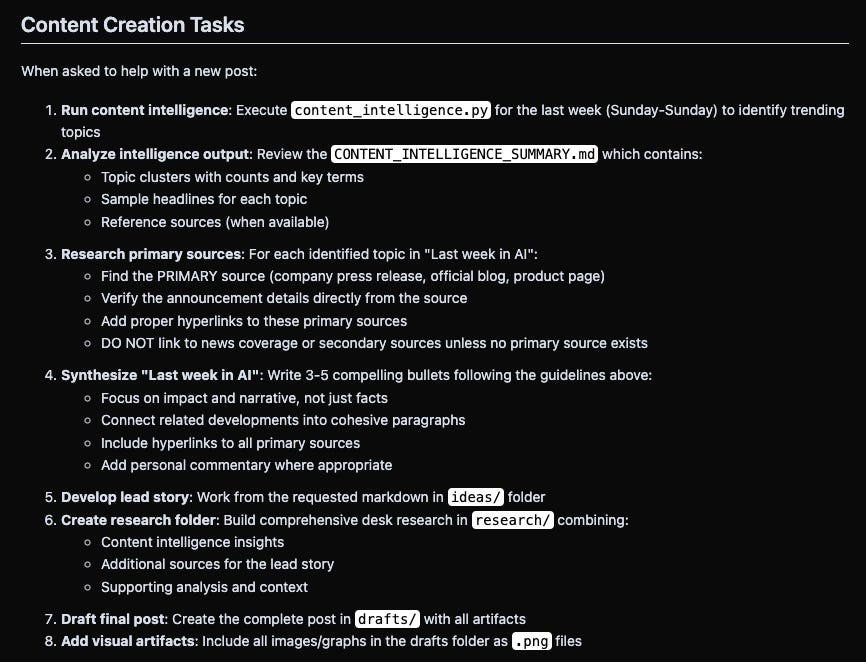
I never use the Claude-generated drafts for anything other than title inspiration, but I am planning to use more of the “Last week in AI” generations and insights directly.
Here is how the prompt to generate the news roundup is currently set up:
“Last week in AI” Section Guidelines
This section should feature 3-5 compelling bullets that synthesize the most important AI developments. Each bullet should:
**Focus on the primary announcement** - Link directly to company press releases, official blog posts, or product pages (NOT news coverage)
**Lead with impact** - Start with what matters to readers, not just what happened
**Connect the dots** - Weave multiple related developments into a single narrative when appropriate
**Add personal context** - Include brief editorial commentary when relevant (”I personally can’t wait to integrate this...”)
**Vary length and structure** - Mix single-sentence updates with longer multi-development paragraphs
**Example structure:**
> In what will likely be the first in a long line of proactive apps and agents, OpenAI launched [ChatGPT Pulse](https://openai.com/pulse) for Pro users—a service that delivers personalized daily updates based on your chat history, memory, and connected apps.
> On the hardware front, OpenAI, Oracle and SoftBank announced the expansion of their [Stargate project](https://stargate.example.com) with five new U.S. AI data center sites. This brings Stargate to nearly 7 gigawatts of planned capacity and over $400 billion in investment over the next three years.
...
The content analyses will continue to be more interactive, and Claude Code is great here—it allows me to set detailed instructions and context, add guidelines and evolve the reference examples while keeping the setup flexible enough to allow me to ask it to work on specific research questions for specific articles.
Topics, tools and technologies
This whole system was built mainly so that I can now write with confidence that “the main story last week was <X>” in the Last week in AI section instead of eyeballing it.
Jokes aside, I’m really excited as to what new insights this content pipeline will bring in the long run. I’ve always been interested in hype cycles as a cultural phenomenon, ever since I stumbled upon De Saussure’s work on the evolution of language way back when.
Tracking these trends over time in a more systematic way will allow me to uncover more patterns than I’ll be able to decipher through brain power alone.
In all, running this research pipeline will set me back around EUR 5 per week (EUR 2.5 in Make.com subscription fees, and ~ EUR 2.5 in Anthropic API credits). Given that it saves me at least two hours of work every week and yields way higher quality insights, I’m mostly disappointed I didn’t implement something like this sooner.
That being said, I can promise is that everything above the line will always remain 100% free-range human writing—even though the content below it will become more and more automated over time.
Last week in AI
OpenAI’s DevDay 2025 keynote just completed, showcasing AgentKit for visual agent workflows, Codex SDK with Slack integration, and Sora 2 API access for video generation. HubSpot used AgentKit to enhance their Breeze AI tool, and a developer built a functioning agent on stage in eight minutes. Combined with their $1.1B+ partnership with AMD for 6 gigawatts of compute starting in late 2026, OpenAI is racing to become the end-to-end AI infrastructure company.
On the model front, Anthropic’s Claude Sonnet 4.5 claimed the coding crown with 77.2% accuracy on real-world software engineering tasks (SWE-bench Verified) and demonstrated 30+ hours of autonomous focus on complex projects. Enterprise results speak for themselves—HackerOne cut vulnerability response time by 44%. GitHub immediately integrated it into Copilot, signaling a potential shift in developer mindshare away from OpenAI.
The infrastructure wars intensified as Samsung and SK joined OpenAI’s $500B Stargate project, committing to 900,000 high-bandwidth DRAM chips monthly for AI data centers. Samsung shares hit January 2021 highs, and SK Hynix surged to 25-year peaks on the news. Meanwhile, Meta is in talks to acquire RISC-V chip startup Rivos to accelerate its custom MTIA AI chip development—apparently Zuckerberg isn’t satisfied with the pace of in-house silicon efforts.
Microsoft brought AI agents to consumers with Microsoft 365 Premium at EUR 19.99/month, bundling higher Copilot limits with access to two reasoning agents previously exclusive to enterprise customers. The bet: consumers will pay double the standard subscription for AI capabilities. The company simultaneously released its Agent Framework in public preview, providing open-source tools for building multi-agent systems in Azure.
I really like this system. How do you fact check here though...is there any layer to help catch hallucinations? I would love to know!
thanks for the shout out Jonas.
we actually have similar workflow where I also process and synthesize everything on Claude Code through my Gdocs while make.com is doing all of information gathering!
I'm currently experimenting to build small app inside my Claude Code project to visualize every content I have published on my newsletter so I can monitor them religiously and use custom command every once in awhile to ask Claude to update all the data.
Thanks for sharing this, love it!